
Python is the go-to programming language for data science … for now. With tremendous growth in other programming languages and the interest in data science rises the question, is Python still the reigning language in the world of data science?
In the late 10’s, Python became increasingly popular as a programming language for data science (DS), competing with languages like R and Matlab. By now, according the PYPL Index (Worldwide) , Python is the most popular programming language since 2018. Only, we see more and more programming languages entering the stage; with (among other benefits) better Cloud Native performances and the ability to run on modern hardware. Modern languages like Rust, Scala and Julia are entering the arena and are becoming true competitors in the world of data science (DS). Is Python still number one, or is it being outperformed on important aspects of what a “good” data science language should have?
PYTHON AS A PROGRAMMING LANGUAGE
Python is a general-purpose programming language designed by Guido van Rossum in 1991. A general-purpose programming language is a programming language that is capable of creating software for a wide variety of problems and application domains. Python is an open-source, object-oriented programming language, that is extremely easy to learn and understand, compared to other programming languages. It comes with a rich set of libraries for a variety of objectives, like mathematics, engineering, data manipulation and so on. Being backed up by a strong community makes Python currently the number one programming language. Numerous guides, tutorials, videos, and documentation are available and easily accessible. Python is a programming language that is also often used for experimentation due to its flexible and versatile nature. It can be used in almost any kind of environment and operating system.
WHAT MAKES A LANGUAGE SUITABLE FOR DATA SCIENCE, YOU ASK?
Within the field of data science, almost all job tasks rely on programming. So, the question, therefore, is which programming languages within this field. To answer that question, it is important to know what kind of tasks a data scientist needs to fulfil and what is expected performance-wise of the programming language. Knowing this will make a difference performing these tasks, otherwise you may suffer in productivity and/or performance.
One of the most important tasks performed by a data scientist is processing and cleaning the data, so that you can perform analyses on the data. Other tasks vary from integrating to storing data, and from exploratory analysis of the data to the fine tuning of machine learning algorithms.
For a data scientist to perform these tasks effectively and efficiently, a programming language needs to be functional. Functional meaning two things; (1) it performs well on the tasks described before – where performance can be measured in both easiness to learn and work with, as well as its actual speed. And (2): functional as in supporting parallel programming and being highly scalable.
A programming language suitable for data science needs to be able to run on modern hardware (e.g. Multi-core CPUs, TPU) and it needs to be cloud ready. These factors have become increasingly important, considering that more and more organizations switch to cloud computing and cloud development.
Perhaps one of the most important features of a data science programming language is a well-developed and established ecosystem and community. With a well-developed and established ecosystem/community, programming languages are complemented with large amounts of functioning libraries, forums, blogs, platforms, and events (to name a few).
Finally, a great DS language should have a gentle learning curve. While it could sound like taking the easy way out, when picking a language based on easiness to learn, a programming language that is easy to learn and use, contributes to efficiency and effectiveness.
WHY OTHER LANGUAGES
So why is it then that we need to consider other languages? Python is the number one programming language for data science for a reason, right?
Well, as a wise man (Albert Einstein) once said: “There is nothing known as “perfect”. It’s only those imperfections which we choose not to see!”. Python seems to be doing great on important aspects, but it also has its imperfections and flaws. Python lacks in speed, is susceptible to runtime errors, and underperforms with memory intensive tasks. So maybe there are aspects to, and possibly opportunities within, other languages that could make them more suitable for performing data science tasks?
POSSIBLE COMPETITORS
Let’s have a look at the current landscape of modern programming languages used for data science and detect some languages that could potentially kick the number one of its pedestal. Why modern programming languages? Well, C, C++, Java and Python are languages that originated in 80’s and 90’s, not something that is called “modern”. These languages were originally not designed to work with Multi-Core CPUs, GPUs, TPUs, Containers and even the Cloud. Of course, some languages adapted themselves to fit in the modern ecosystem, yet the new modern languages were fundamentally designed to exploit these modern-day features of programming. Three of such languages are Go, Rust, and Julia. Let’s see in what way they could compete with the reigning programming language.
Go
The first language to consider is Go (developed in 2007, released 2012; Google). Go is an open-source programming language that is completely aimed at efficiency, reliability as well as simplicity. It is built to support concurrency, designed to run on multiple cores, and it scales as more cores are added. Go is mostly used for System Programming, Serverless Computing and Cloud-Native Development. Moreover, lots of infra-tools are written in Go, like Docker, Prometheus, and Kubernetes. The first advantage of Go is that it is a language that is easy to learn and understand compared to other languages. Its syntax is fairly simple, of course there are some exceptions, but you can develop apps in a faster manner compared to other languages. Secondly, Go is a fast language! Why? Go is compiled to machine code, where it compiles faster than most programming languages like Java and C/C++. In addition, Go comes with lots of libraries and packages, and is still growing in popularity, meaning that the last word has probably not yet been spoken on this language.
Rust
Next up is the programming language Rust (developed in 2010, released 2015; Mozilla Research). Rust is a statically-typed programming language, meaning that variable types are explicitly declared and therefore determined at compile time. The main advantage of this programming language is that memory errors and concurrency issues (especially problematic in languages like C and C++). Rust has a feature that is called ‘zero-cost abstractions’ where you don’t pay for features you don’t use. Rust was built with efficiency and speed in mind, where it is mainly focused on safety and performance. In addition, Rust comes with thousands of code libraries – named crates – that are like accessible containers, comparable to packages in other languages.
Julia
The last language to consider is Julia (developed in 2009, released in 2012; Jeff Bezanson, Alan Edelman, Stefan Karpinski, Viral B. Shah). Julia is a fast, dynamically-typed programming language especially designed for concurrent, parallel, and distributed computing; where it really shines the most when it comes to numerical and scientific computing. Julia’s syntax is similar to formulas often used by non-programmers, making it a language that is easier to learn for users with a math background. Julia was made for speed, giving it a considerable speed advantage compared to common data science and statistics languages. In addition, a real game changer (according to practitioners) is the feature of multiple dispatch. With multiple dispatch a function or method can be dynamically dispatched based on run-time/dynamic type or some other attribute/argument. In other words, the programmer can write a function multiple times to handle different types.
“A COMPARISON IN THE WILD”
Well, this all sounds really promising; let’s put it to the test. Taking some “basic” machine-, and deep learning algorithms, together with datasets that are frequently used for data science projects and let’s compare these programming languages.
K-means clustering
K-means clustering was the weapon of choice for the first comparison. With k-means it is possible to group datapoints within clusters. A cluster here refers to a collection of data points that are aggregated together due to certain similarities. It is an unsupervised algorithm that makes inferences from the input dataset using only input vectors, without knowing the outcomes (labels). For this comparison, a dataset of 300 random data points was created with four centers, using sklearn.datasets.make_blobs.
Random forest classification
For the second comparison, a Random Forest classification algorithm was chosen. A random forest is a classification algorithm that creates many trees. For building these trees, the algorithm uses bagging and feature randomness. It creates multiple uncorrelated trees, a forest, where the prediction of the forest is more accurate than of each of the individual trees. The data used for this comparison is the well-known iris flower dataset. This dataset consists of three classes of 50 instances each, where each class is a type of iris: either Setosa, Versicolour, and Virginica, with the attributes sepal-, and petal-length, together with the sepal-, and petal-width. Where in contrast to the k-means clustering comparison, the labels are indeed given, making it a supervised learning problem.
CNN
The last comparison made is using a Convolutional Neural Network (CNN or ConvNet). A CNN is a deep learning algorithm that is mainly used for image recognition, image classification, object detection along with others. In this comparison, the CNN is used for image classification of the MNIST (Modified National Institute of Standards and Technology) dataset. This dataset contains 60,000 training and 10,000 test images, where each image is a black and white (bilevel) handwritten digit. As with the random forest comparison, the labels of the images are known, making it a supervised deep learning problem.
“THE SUSPENSE IS KILLING ME”
The following figure shows the results obtained when running the models. For making a fair comparison, the models were all caried out on the same CPU[2]. Of course, there were possibilities to improve the results, e.g., GPU acceleration, yet it was chosen not to, due to a fast implementation. The focus of the analysis lies mainly on the exploration of the DS languages; , or do you need to built them from scratch? Therefore, the optimalization of the models lies outside the scope of this analysis.
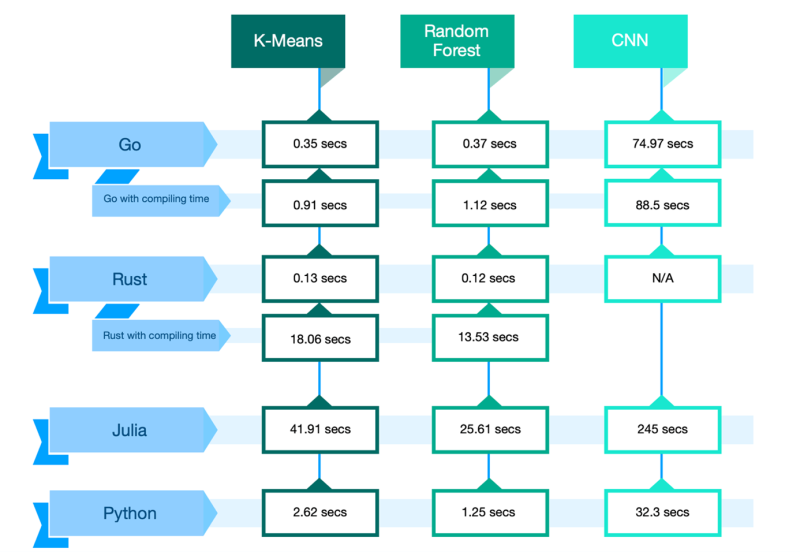
*Where Julia is a “just ahead of time” compiler, the seconds shown, are from the second run.
Figure 1: Runtimes per language per case
The results of the use cases show that Rust and Go, when compiled, are indeed a lot faster compared to Python for the random forest and k-means case. Where Rust is even more than twice as fast as Go, if compiled. But here Go does show its strength as a fast-compiling language, as it even outperformed Python with compilation.
For the CNN use case, however, Python is taking the crown. Here, the smaller data science community for Rust really showed as it was not possible to get the available CNN crates working (Library: Out of the Box). This was mainly due to available CNN crates running on older Rust versions and little documentation and explanation. Of course, a well-seasoned Rust programmer would be able to create a wonderful CNN model, yet one of the features of a great data science language is a gentle learning curve. And gentle, it was not.
Comparing the use cases, you can clearly see that Julia is performing the worst of all languages. This was due to slow fileIO; loading data from a CSV file into a data frame, which took most of the running time. As a novice in Julia, it is possible (and very likely) that the efficient way of loading the data frame into Julia was overlooked. Nevertheless, a fast fileIO is important for DS, especially in the time of Big Data.
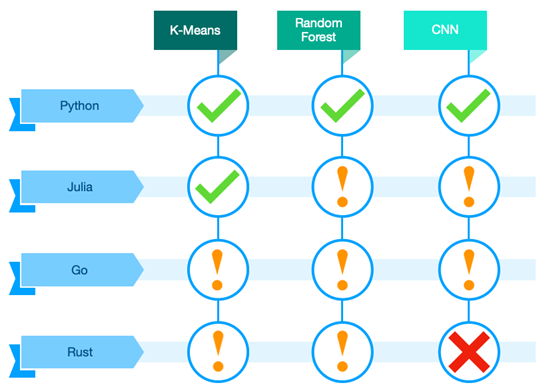
Figure 2: Overall conclusion based on implementation, performance, community and learning curve
Looking at the implementation of the use cases, Python is a clear winner. All three use cases were easy to implement, there were lots of examples available, and the code was easy to interpret (as in easy to understand and implement). This was of course expected, with Python being the go-to language with data science.
As with the other three languages, even though some performed well, the implementation didn’t run as smoothly as expected, other didn’t run at all… Julia has lots of potential, where you can find commendable examples online for the K-means use case. The implementations became a bit more difficult for the other two cases. However, it is also believed that Julia is not yet where it could be, so with the growth of the language in the back of the mind, Julia can become a real pearl within the world of data science.
For the Go and Rust use cases, it was way harder to find good examples online, mainly due to the small community of the programming language. Yet, Rust is still in its growing phase where in the future it might be easier to implement these cases.
TO SWITCH OR NOT TO SWITCH, THAT IS THE QUESTION
These modern languages show some valuable features and show potential in some fields. However, Python still shows its true value, especially with the comparison in the use cases. Of course, this comparison could have been carried out in a different manner; other machine learning algorithms and problems could have been chosen, different hardware (to name a few). Yet in most of the use cases Python is a clear winner. Do note that, under the hood, Python is heavily lifting on C/C++. This makes Python the synthetic sugar that glues these low-level algorithms together, making them easy to use. Although Rust is not as easy to learn, it has these same capabilities due to the availability of multiple crates (libraries), therefore Rust might be a good candidate for this aspect as well.
SO, SHOULD YOU CONSIDER SWITCHING TO OTHER LANGUAGES?
Well… learning other programming languages is always a good idea. Not only to increase your own skill level, but you also acquire more tools to get the job done! Knowing the strengths and weaknesses of languages makes it easier for you as a programmer to pick the right tool for the job. Now you know that if you want to implement a CNN, it is probably not the best idea to use Rust for it. However, when performance is important, you should definitely consider Rust.
Main point to take away is that for every problem there is a solution, and choosing the right language depends on what task needs to be fulfilled, combined with, of course, your level of experience and knowledge. Knowing what you can do with what language contributes to your skills as a programmer. Keep looking around, there might be popping up some interesting new DS languages…
This blog was written as an addition for the meetup “data science zonder python: talen van de toekomst”. For the video you can click here, for the code is referred to our github.
[1] https://pypl.github.io/PYPL.html
[2] Macbook Pro 2019, Processor: 2.4 GHz Intel Core i5 (i5-8279U), RAM: 16GB of 2133 MHz LPDDR3, GPU: Integrated GPU Inter Iris Plus Graphics (Not relevant for tests), OS: macOS Monterey, version 12.0.1